











Contents
DifyのRAG構成で誤回答を徹底的に減らす実践ガイド:社内AIツール内製チーム向け
社内向けのAIチャットボットをDifyで内製すると、わりと早い段階で困るのが「それっぽいけど、違う」回答です。たとえば就業規則や申請ルールのように“最新版が正義”の領域で、旧版PDFが混ざったまま取り込まれていると、正しい文書があるのに平気で昔の運用を答えてしまいます。こういう事故は、LLMの性能というより、ナレッジの入れ方と検索の当たり方で起きることが多いです。
DifyのRAGは、ナレッジから根拠を引いて回答させられるぶん、LLM単体より誤答を抑えやすいのは確かです。ただし、構成や設定が雑だと「根拠があるのに外す」「関係ないチャンクを拾って自信満々に答える」といった別タイプのミスが出ます。本記事では、社内AIツールを“配る側”の開発チーム向けに、誤答を減らすためにどこを見直すべきかを、設計→設定→運用の順で整理します。
扱うのは、ナレッジベースの作り方、チャンクの切り方、Hybrid Search / Rerankの考え方、回答側のガードレール(推測させない・根拠を出させる)までです。最後に、テストクエリとログレビューで改善を回すやり方も触れます。すでに試していて「なんか外す」が気になっているチームでも、これから本格導入するチームでも、そのままチェックリストとして使える形を目指します。
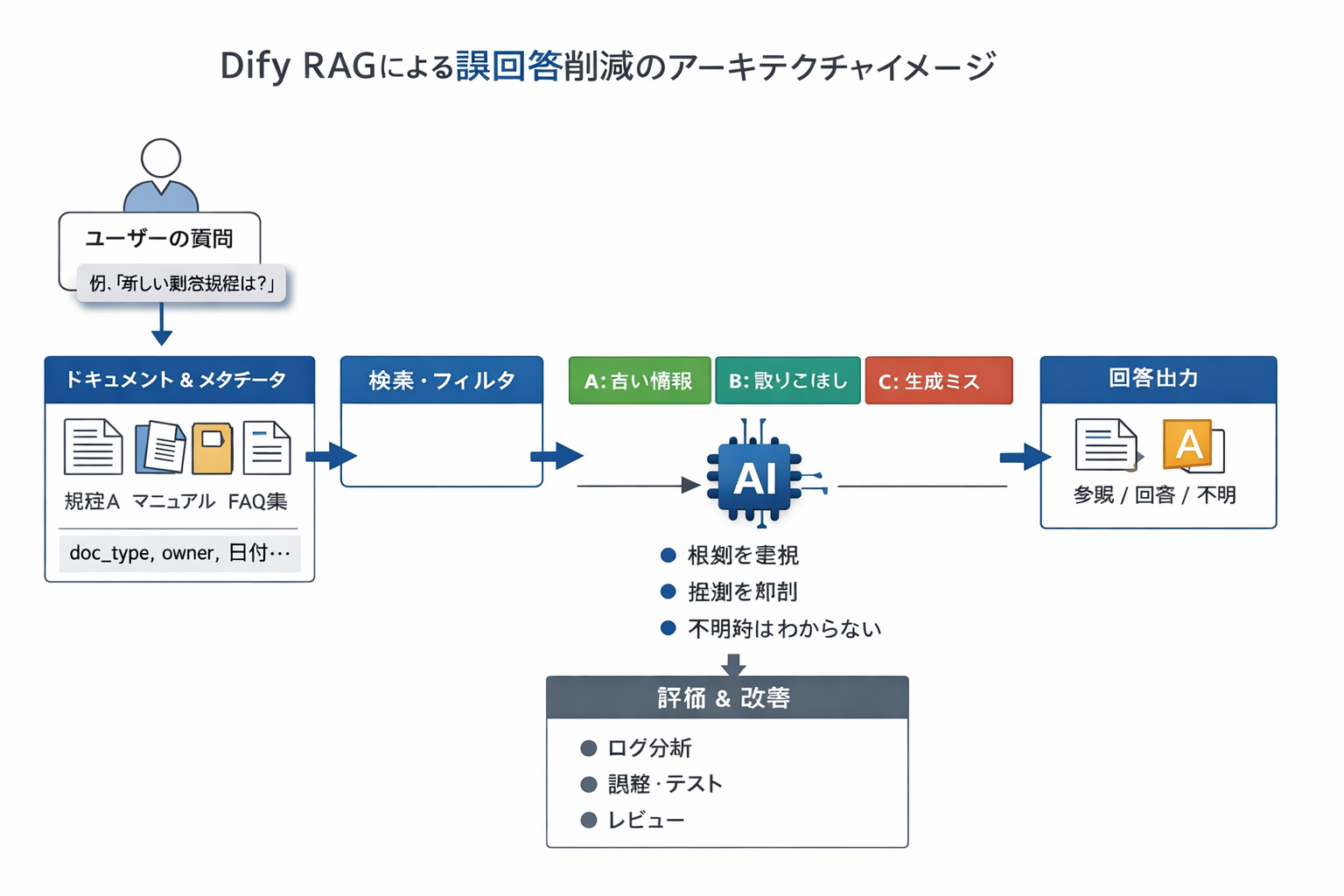
Dify RAGと誤回答の関係を正しく捉える
最初に押さえておきたいのは、RAGを入れた瞬間に誤回答がゼロになるわけではない、という点です。DifyのRAGは「質問→関連チャンクの取得→そのチャンクを根拠に回答生成」という流れをGUIで組めるのが強みですが、どこか一段でもズレると誤答が出ます。しかも、LLM単体のハルシネーションとは違って、RAGの場合は“参照元が間違っている”形でそれっぽく答えてしまうのが厄介です。
原因を切り分けるときは、誤回答をまとめてLLMのせいにしないのがコツです。実務では、少なくとも次の4層に分けて見た方が早いです。
- (1) ナレッジ自体が正しいか(最新版か、一次情報か、混在していないか)
- (2) 検索で“正しいチャンク”を拾えているか(取りこぼし/ノイズ混入)
- (3) 拾った根拠に沿って答えているか(勝手な補完をしていないか)
- (4) 質問文が検索に向く形か(略語・曖昧さ・前提不足がないか)
Difyはフローの中でKnowledge RetrievalとLLMを分けられるので、「このミスは検索の問題か、回答生成の問題か」をログから追いやすいです。まずはこの分解で、改善の打ち手を間違えないところから始めるのが安全です。
なお社内向けAIだと、誤回答のダメージは領域によって差があります。勤怠・人事・経理のように“間違えたら現場が混乱する”領域は、無理に即答するより「根拠が見つからないので確認してください」と返す方が、結果的に信頼されます。ゴールを「何でも答えるAI」ではなく「答えられるものを確実に、答えられないものは誤答しない」に置くと、その後の改善サイクルも回しやすくなります。
導入初期は「まずは誤回答が致命傷になる領域から固める」くらいの方針を、経営・現場と先に握っておくと楽です。最初から万能を目指すと、ちょっとした外れが信用失墜につながりやすいからです。
3分でできる! 開発費用のカンタン概算見積もりはこちら
誤回答パターンの分解:どこでズレが生まれているのか
DifyのRAGで誤回答を減らすとき、いきなり設定をいじるより先にやった方がいいのが「ズレの種類」を揃えることです。誤答といっても、原因が違うと効く打ち手も真逆になります。よくあるのは、次の4パターンです。
- パターンA:ナレッジが古い/混ざっている(参照元がズレている)
- パターンB:検索が外れている(正しい情報はあるのに拾えていない)
- パターンC:拾えているのに、生成で盛っている(根拠外の補完)
- パターンD:質問が曖昧/社内用語が強すぎる(検索に向かない入力)
まず多いのがパターンAです。たとえば「経費精算の上限」や「勤怠の締め日」のようなルールは改定が入りやすく、古い規程PDFと最新版が同じナレッジに入っているだけで事故ります。検索自体は正しく動いているのに、たまたま旧版のチャンクが上位に来てしまい、回答もそれに引っ張られる――という形です。このタイプは、検索パラメータを頑張っても限界があるので、先に文書の棚卸し(最新版の一本化/旧版の隔離)をやる方が早いです。
次に多いのがパターンBです。これは「正しい文書は入っているのに、top-kに入ってこない」タイプ。原因はだいたい2つで、(1)チャンクの切り方が粗くて、必要な一文が埋もれている/(2)社内用語の揺れでマッチしない、です。
具体例を出すと、情シス系の手順で「VPNの申請」なのか「リモート接続」なのか呼び方が人によって違う、みたいなケースがあります。キーワードだけに寄せると「VPN」という単語が出ていない文書を取りこぼしますし、逆にベクトル検索だけだと似た意味の別手順(たとえば“端末申請”)を拾ってしまうこともあります。こういうときはHybrid Searchを使いつつ、略語辞書や同義語のQ&Aを足す、といった“地味だけど効く”対策が刺さります。
パターンCは「検索は当たっているのに、回答がズレる」ケースです。ログを見ると、ちゃんと正しいチャンクを取得しているのに、LLMが自分の知識で補完して答えを作ってしまう。社内ボットだとこれが一番怖いです。対策はシンプルで、「根拠にないことは言わない」「根拠の引用を必須にする」「根拠が薄いときは“不明”で止める」をプロンプトと出力フォーマットで固定します。ここを曖昧にすると、“それっぽいけど違う”が戻ってきます。
最後のパターンDは、ユーザー側の入力が原因です。社内の略語だけで質問される、前提が省略される、同じ言葉が部署によって意味が違う――このあたりは、どんなRAGでも起きます。たとえば「S申請ってどうやる?」のように、略語だけで投げられると検索が迷子になります。こういうときは、入力の前処理で略語展開をするか、ナレッジ側に「略語→正式名称→関連手順」の辞書チャンクを用意しておくと、外れ方がかなり減ります。
誤回答が出たときは、まずログを見て「A〜Dのどれか」をラベリングするのがおすすめです。毎回の修正が“思いつき”にならず、改善が積み上がります。
ログレビューの観点例
1. 正しい情報(最新版)がナレッジに入っていたか/2. 検索結果(top-k)に正しいチャンクが入っていたか/3. 回答が根拠の引用に沿っているか/4. 質問文が略語・前提不足で迷子になっていないか。まずはこの順で見ます。
ナレッジとチャンクの設計でRAGの当たりを上げる
誤回答を減らすうえで、一番効くのはナレッジ設計です。ここが曖昧なままだと、検索やプロンプトを頑張っても限界が来ます。逆に、ナレッジの入れ方が整っていると、RAGはかなり素直に当たるようになります。
最初に決めたいのは「何を正とするか」です。社内には、規程・手順書・FAQ・議事録・個人メモなど、いろいろな情報が散らばっていますが、全部を同じ土俵に載せると事故が増えます。特に地雷になりやすいのは次のタイプです。
- 改定が多いのに「最新版/旧版」の区別がついていない規程PDF
- 担当者のメモやSlackのコピペなど、背景文脈がない断片情報
- 製品Aの仕様と製品Bの仕様が同じフォルダに混ざっているドキュメント群
- ドラフト(検討中)の資料が正式版と並んでいる状態
まずは「正式版の一次情報(規程・公式手順・確定したFAQ)」を優先して入れ、それ以外は別ナレッジに分けるか、参照順位を下げる方が安全です。やみくもに量を増やすより、正しい情報が“迷子にならない”状態を作るのが先です。
次に効いてくるのが、メタデータの持たせ方です。全文検索だけに頼ると、同じ単語が出てくる別文書を拾ってしまいます。社内向けだと「部署ごとにルールが違う」「制度が年度で変わる」「プロダクトや顧客区分で条件が変わる」などが普通にあるので、絞り込みできる前提を作っておくと誤答が減ります。
最低限つけておくと効きやすいメタデータは、たとえばこのあたりです。
- doc_type:規程/手順書/FAQ/仕様書 など
- owner:主管部署(人事・経理・情シスなど)
- effective_from / effective_to:適用期間(わからなければfromだけでも)
- scope:対象(全社/特定部門/プロダクトA/顧客区分など)
- status:正式版/ドラフト(draftは原則検索対象から外す)
「この質問は人事なのでHRの最新だけ見る」「プロダクトAの問い合わせはAの仕様書だけ見る」といった制御ができるだけで、旧制度や別製品を拾う事故はかなり減ります。
チャンク分割は、“何を答えるときに前提が必要か”で方針を変えるのがおすすめです。規程や契約書のように例外条項・条件が絡む文書は、段落だけで機械的に切ると前提と結論が別チャンクになりやすく、検索は当たっているのに回答がズレる原因になります。
そういう文書では、DifyのParent-childを検討すると扱いやすいです。検索は子チャンク(短い断片)で当てつつ、回答生成には親チャンク(章・節などのまとまり)を渡して文脈を残す、という考え方です。たとえば「申請できる条件」と「例外」が同じ親の中に残っていれば、「条件だけ拾って誤答する」確率が下がります。
一方で、FAQのように1問1答で完結する情報は、むしろQ&A単位でチャンクにしておく方がシンプルです。文書の性質に合わせて、チャンク戦略を切り替えるのがコツです。
改定が多い文書は「最新版だけを置く場所」を決めて、そこだけをナレッジに同期する/文書冒頭に「目的・対象者・適用範囲」を1段落で書いておき、その段落がチャンク先頭に残るようにする/「ドラフト」「正式版」をメタデータで分け、検索の対象を明確にする――このあたりは地味ですが効きます。
3分でできる! 開発費用のカンタン概算見積もりはこちら
Retrievalと生成ガードレール:Dify RAG設定の実務ポイント
ナレッジとチャンクが整ったら、次は「どう拾って、どう答えさせるか」です。ここで意識したいのは、Retrieval(検索)とAnswer(生成)を同じ“精度”として扱わないことです。検索で外れるのと、生成が盛るのでは、直し方がまったく違います。まずはログで、どちら側の事故かを切り分ける前提で調整していきます。
Retrieval側で現場に効きやすいのは、Hybrid SearchとRerankの使い分けです。社内ドキュメントは、略語・部署語・固有の言い回しが多く、意味検索(ベクトル)だけでは拾いにくいことがあります。逆にキーワードだけだと、同じ単語が出てくる“別制度・別製品”を拾いやすい。だから併用して、最後にRerankで「本当に関係ある順」に寄せるのが基本戦略になります。
たとえば、次のようなときはHybridが効きます。
- 「VPN」「情シス申請」など、略語や部署語が強い(キーワードの強みが出る)
- 「リモート接続」「在宅端末」など、言い換えが多い(ベクトルの強みが出る)
- 制度名が似ていて取り違えが起きやすい(Rerankでノイズを落とす)
次に、よく効くのがtop-kとスコア閾値の考え方です。ここは「多く取れば正しい」でも「絞れば正しい」でもなく、ドメインで最適が変わります。
- 誤答が致命的な領域(人事・経理・法務など):取りこぼしを避けるために、まずは候補を少し広めに拾い、Rerankやフィルタでノイズを落とします。そのうえでLLMに渡す量は絞り、“根拠が薄いなら不明で止める”に寄せます。
- ライトなFAQ領域:スピード優先で候補を絞り、多少の取りこぼしは運用で拾う(フィードバック→追加)に寄せる、という考え方もあり得ます。
ここでありがちな失敗は「拾ったチャンクを全部LLMに渡す」ことです。ノイズが増えると、LLMは関係ない文も“根拠”として扱い始めます。候補は多めに拾っても、最終的に渡すチャンクは必要最小限にする方が、結果として誤回答が減りやすいです。
次にAnswer(生成)側のガードレールです。社内ボットで一番避けたいのは「根拠が薄いのに、それっぽく断言する」状態なので、LLMにやっていいこと/ダメなことを明示して、出力も型で縛ります。
おすすめは、次の3点をセットで入れることです。
- 推測禁止:渡されたチャンクに書いていないことは言わない
- 根拠必須:結論と一緒に、根拠となる引用(または該当箇所)を出す
- 不明時の挙動:該当情報がない場合は「不明」とし、確認先(担当部署/公式手順)へ誘導する
出力フォーマットも固定しておくと、ユーザーが“根拠のない回答”に気づきやすくなります。たとえば、次のような形です。
出力フォーマット例
結論:(まず短く答える)
根拠:(引用:文書名 / 該当箇所)
注意点:(例外・条件があれば)
参照:(文書名・更新日が分かるなら)
これをやると、たとえ完全に正解でなくても「どこを根拠にそう言っているか」が残るので、社内運用が回りやすくなります。逆に、根拠を出さない回答を許すと、誤回答の検知もレビューも難しくなります。
プロンプト例(抜粋)
「あなたは社内ナレッジに基づいて回答するアシスタントです。与えられたコンテキスト以外の情報で推測してはいけません。該当情報がない場合はその旨を伝え、担当部署または公式手順書への確認を促してください。回答は『結論/根拠(引用)/注意点/参照』の形式で出力してください。」
最後に小ネタですが、誤答が出やすい領域ほど「回答の口調」を少し弱めるのも効きます。断言ではなく「文書上は〜となっています」「〜の場合は担当部署に確認してください」といった書き方に寄せるだけで、ユーザー体験が安定しやすいです。社内AIは“速さ”より“信頼”が勝つ場面が多いので、ここは割り切った方が結果的に定着します。
評価と運用の仕組みづくり:改善を止めないために
RAGの調整は、1回チューニングして終わりではありません。社内ルールは改定されますし、問い合わせの傾向も変わります。なので大事なのは「誤回答が出たら直す」だけではなく、「いつの間にか悪化していた」を早めに検知できる仕組みを作ることです。
最初にやると効くのは、テスト用の質問セット(テストクエリ)を作ることです。立派なベンチマークを最初から目指す必要はなく、まずは“事故りやすい質問”だけで十分です。たとえば、こういうものから集めます。
- 人事・経理・情シスなど、誤答すると影響が大きい領域の定番質問
- 制度名が似ていて取り違えが起きた質問(過去に実際に外したもの)
- 略語や社内用語が強い質問(部署語で聞かれがちなもの)
- 「例外」「条件」「いつから適用?」のように前提が必要な質問
このテストクエリに対して、最低限次の2つだけを決めておくと、改善が回りやすくなります。
- 期待する結論(短くてOK。正解の言い回しまで固定しなくてよい)
- 根拠として参照してほしい文書(できれば文書名や章)
ここまで決めておけば、「設定を変えたら何が良く/悪くなったか」が見えるようになります。逆に、テストクエリがないまま調整すると、手触りで“良くなった気がする”だけになりがちです。
評価指標は、最初はシンプルにした方が続きます。おすすめは、次の3つです。
- 外したかどうか(誤回答/不明の判断が適切か)
- 根拠が出ているか(引用や参照が付いているか)
- 参照元が正しいか(旧版や別制度を拾っていないか)
Recall@kなどの検索指標ももちろん役に立ちますが、最初から数式っぽい指標だけに寄せると運用が止まりやすいです。まずは“人が見て判断できる”指標で回して、必要になったら検索指標を足すくらいが現実的です。
誤回答が出たら、原因を毎回同じ観点で切り分けます。前の章で出した4層(ナレッジ/検索/生成/質問)でラベルを付けるだけでも、改善の質が上がります。たとえばこうです。
- ナレッジ原因:最新版が入っていない/旧版が残っている → 文書の入れ替え・隔離
- 検索原因:正しいチャンクがtop-kに入らない → チャンク再分割/同義語追加/HybridやRerank調整
- 生成原因:根拠があるのに盛る → プロンプト強化/出力形式の固定/渡すチャンクの整理
- 質問原因:略語・前提不足 → 略語辞書/入力ガイド/追質問(確認質問)の導入
この“分類→打ち手”をテンプレ化しておくと、誰が見ても同じ方向に直せます。属人化が減るので、社内ボットの運用ではかなり大きいです。
運用は、月1のレビュー会でもいいですし、最初は隔週でもいいです。大事なのは頻度より、見るものを固定することです。おすすめの定例アジェンダは、この3つだけです。
定例レビューで見るもの(例)
1. 直近で外した誤回答トップ3(原因ラベルと対応)
2. ナレッジ更新(追加・削除・改定)の一覧と影響
3. テストクエリの結果(前回から悪化したものがないか)
特に、人事・法務・経理のようにリスクが高い領域は、開発チームだけで判断しない方が安全です。“業務側の目”でレビューしてもらう仕組み(例:月1で10分だけ確認してもらう)を作ると、誤回答の芽を早めに潰せます。
そして最後に、ユーザーからのフィードバック導線です。チャットUIに「役に立った/微妙」「根拠が違うかも」くらいの軽いボタンを置いておくと、改善ネタが自然に集まります。誤回答をゼロにするのは現実的に難しいので、“外したら早く直る”状態を作る方が、定着には効きます。
レビューが続かない原因は、だいたい「見る項目が多すぎる」か「判断基準が曖昧」のどちらかです。テストクエリはまず20個程度から、指標は“外したか/根拠があるか/参照元が正しいか”の3つから始めると、現実的に回しやすいです。
3分でできる! 開発費用のカンタン概算見積もりはこちら
まとめ:Dify RAGで社内AIの信頼を積み上げる
本記事では、Difyで社内向けRAGを作るときに誤回答を減らすためのポイントを、ナレッジ設計→チャンク→検索→生成ガードレール→運用という順で整理しました。やることは多く見えますが、コツはシンプルで、「どこでズレたか」を分解して、正しい層に手を入れることです。
- 旧版やドラフトが混ざっているなら、まずナレッジの棚卸しから
- 正しい情報があるのに拾えないなら、チャンクと検索(Hybrid / Rerank)を見直す
- 拾えているのに盛るなら、推測禁止・根拠必須・不明時の挙動を固定する
- 質問が原因なら、略語辞書や入力ガイドで“聞き方”を整える
社内AIは、一度「信用できない」と思われると利用が止まりやすい一方で、根拠が明示されて誤回答が減ってくると、じわじわ現場に定着します。最初から万能を狙うより、リスクが高い領域から確実に固めて、改善サイクルを回し続ける方が結果的に早いです。
誤回答をゼロにするより先に、「根拠がないなら不明で止まる」「どの文書を見たか分かる」を徹底すると、事故が減ってレビューも回しやすくなります。ここが整うと、追加学習や最適化も効きやすくなります。
「どこから直せばいいか分からない」「設定をいじっているのに外れ方が変わらない」といった場合は、まず原因の層(ナレッジ/検索/生成/質問)を一緒に切り分けるところから整理できます。たとえば、次のような状態だと短時間でも改善ポイントが見つかりやすいです。
- 外したログがいくつか残っている(質問文・取得チャンク・回答が分かる)
- 参照してほしい“正しい文書”が社内で合意できている(最新版がどれか分かる)
- まず固めたい領域(人事/情シスなど)の優先順位がある
ソフィエイトでは、ナレッジの棚卸し、チャンク設計の見直し、検索設定(Hybrid / Rerank)の調整方針、テストクエリと回帰チェックの作り方などを、社内で回る形に落とし込むご相談もお受けしています。お問い合わせ・無料相談はこちら
株式会社ソフィエイトのサービス内容
- システム開発(System Development):スマートフォンアプリ・Webシステム・AIソリューションの受託開発と運用対応
- コンサルティング(Consulting):業務・ITコンサルからプロンプト設計、導入フロー構築を伴走支援
- UI/UX・デザイン:アプリ・Webのユーザー体験設計、UI改善により操作性・業務効率を向上
- 大学発ベンチャーの強み:筑波大学との共同研究実績やAI活用による業務改善プロジェクトに強い










コメント